
Step-by-step guide to reading the leaked militia chats yourself
Welcome to the second installment of my series on the Paramilitary Leaks! In case you missed it, the first installment is here: Exploring the Paramilitary Leaks. Since I published that, several people reached out offering to help. We now have a private Signal group of researchers working on this together, and a git repository of our code so far – much of the code was written by people who are not me, which I'm very excited about. It makes the research go so much faster, and it means this is a real collaboration.
I ended my last post with a challenge: write a script that parses through the dozens of exported Telegram chats and saves them all in a SQL database to make researching them easier. We have that now!
In this post, I'll show some visualizations of the Paramilitary Leaks dataset as a whole, explain how to use our code to build your own SQL database based on the leaked data, and explain how to get started researching it yourself using an excellent tool called Datasette. Finally, I'll go over some research workflow recommendations.
This project is an interactive experience! If you're interested in this dataset, please subscribe to get these posts emailed directly to your inbox. If you're subscribed, you can post comments. If you have questions about the dataset or my finding or anything else, or if you have suggestions on what parts of it to dig into, post comments and I'll engage. If you want to support my work, considering becoming a paid supporter.
You're currently reading the second installment in this series.
Visualizing the data
Before the step-by-step instructions, I want to show off some graphics. Hacker-journalist EJ Fox, who reached out offering to help with this project, has started making some awesome data visualizations of the Paramilitary Leaks dataset. He also wrote a blog post explaining his workflow.
Here's a breakdown of the 52,161 files in the dataset.
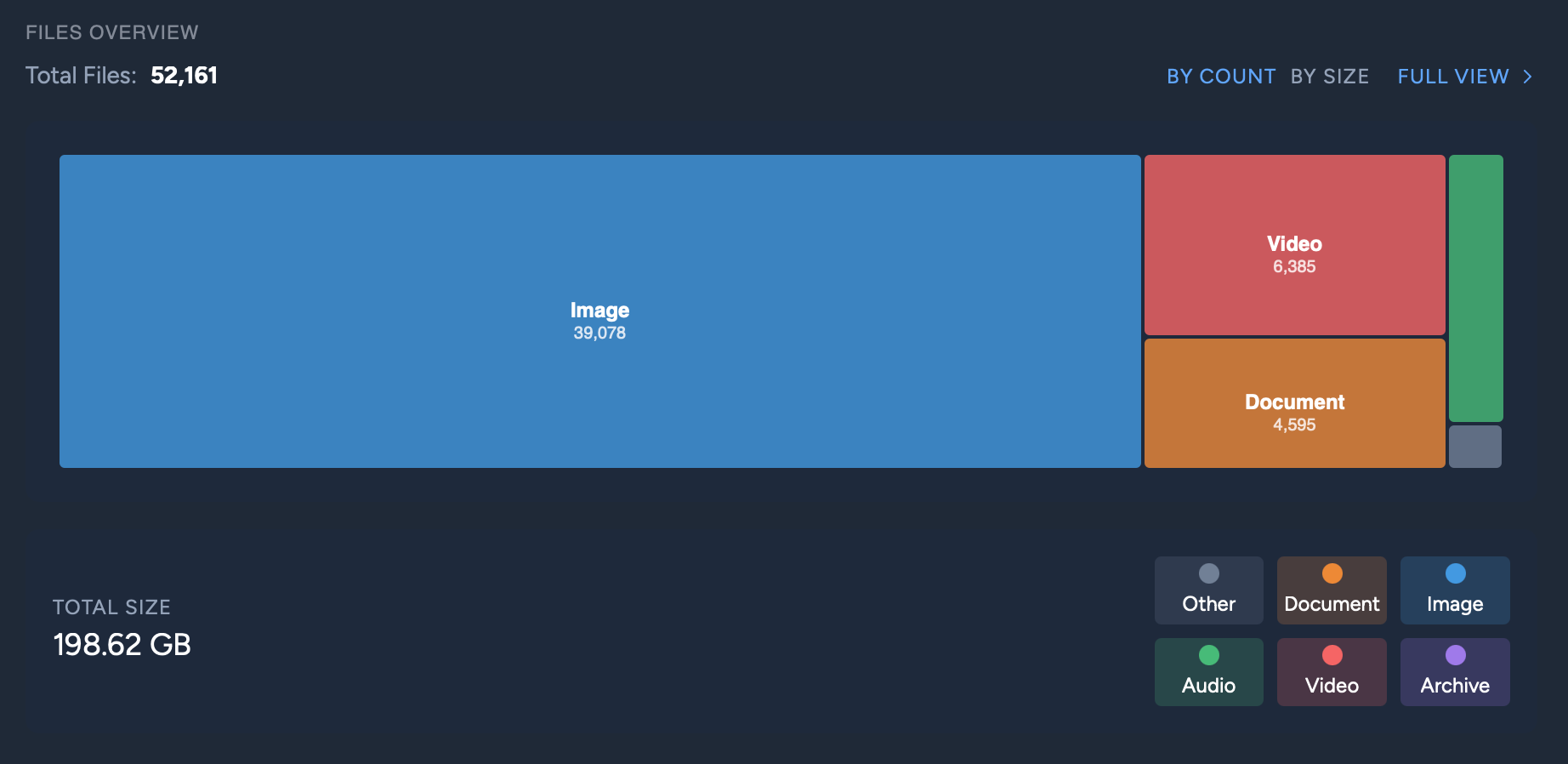
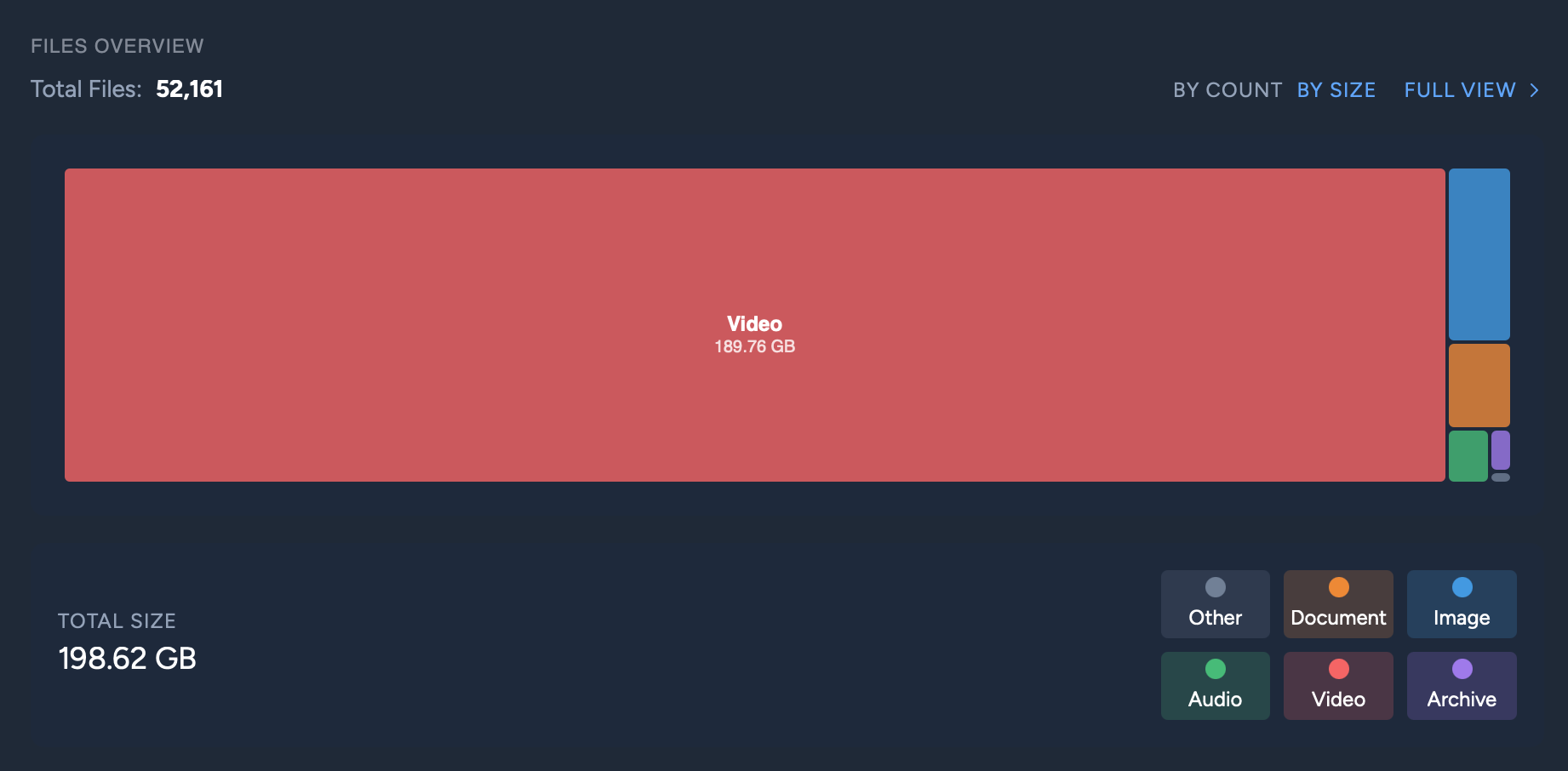
While browsing through the data, I've found that people frequently post video messages, just as a form of communicating with the group. There are also some videos of AP III militia members on the streets.
But unfortunately, there are also quite a few videos that are things like entire conspiracy documentaries, full episodes of Tucker Carlson, and so on. If you participate in this project, sorry for wasting so many gigabytes of precious disk space on nonsense.
Download the dataset
Ready to get started? To begin with, you need a local copy of the data.
If you haven't already, the first thing you need to do is download a copy of the Paramilitary Leaks dataset. The DDoSecrets website shows you the download options, including downloading it using BitTorrent or direct downloads from their download server.
The Paramilitary Leaks files are compressed using 7-Zip. After you download them, extract each 7z file. On my computer, the extracted data is in the folder /media/micah/datasets-ssd/2025-Paramilitary-Leaks/extracted.
Build your SQL database
To use the code that builds up a SQL database, you will need to install Python and Git. After installing Python, you will also need to install Poetry.
Open a terminal and switch to a folder to keep your code (I just call mine code), for example:
mkdir code
cd codeClone the project's git repository:
git clone https://github.com/micahflee/paramilitary-leaks.gitThis will create a new paramilitary-leaks folder. Change to that folder and install the Python dependencies using Poetry (I'm assuming you have successfully installed Python and Poetry):
cd paramilitary-leaks
poetry installThis project includes a command line tool called tasks with just one command, build-db. You can run this command like this:
poetry run tasksThe output should look something like this:
$ poetry run tasks
Usage: tasks [OPTIONS] COMMAND [ARGS]...
Crunching data in the Paramilitary Leaks datasets
Options:
--help Show this message and exit.
Commands:
build-db Build a SQLite3 database based on the Paramilitary Leaks datasetIn order to build the SQL database, you need to know the full path of where your copy of the dataset is. I told you above that mine (on the Ubuntu laptop I'm using) is /media/micah/datasets-ssd/2025-Paramilitary-Leaks/extracted. Figure out the path of where your dataset is. If you're on a Mac, it's probably something like /Volumes/usb-disk/Paramilitary-Leaks/extracted, and if you're in Windows it's probably something like D:/Paramilitary-Leaks/extracted.
Finally, build your local SQL database like this, replacing the path to my copy of the dataset to wherever yours is:
poetry run tasks build-db /media/micah/datasets-ssd/2025-Paramilitary-Leaks/extractedThis will loop through every folder in your dataset looking for exported Telegram chats (message*.html files). For each of these files, it will loop through the HTML slurping up all of the messages and saving them in a SQL database. Here's what it looks like:
Generating a SQL database from the Paramilitary Leaks files
When it's done running, you should have a 55 MB file called output/data.db in your paramilitary-leaks folder. This is your SQLite3 database!
Browse the database with Datasette
Before this project I had only briefly heard about Datasette, a tool for exploring and visualizing data, but I had never actually used it myself. Some of the people contributing to the project use it though so I thought I'd try it out and I can confirm: it's excellent. Datasette is a dependency of the paramilitary-leaks project, so you actually already have it installed.
To get started, run:
poetry run datasette ./output/data.dbThe output should look something like this:
$ poetry run datasette ./output/data.db
INFO: Started server process [252653]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8001 (Press CTRL+C to quit)This will run the Datasette server locally on your computer at http://127.0.0.1:8001.
Load that URL in a web browser to access it. If you click on the data database, it should look like this:
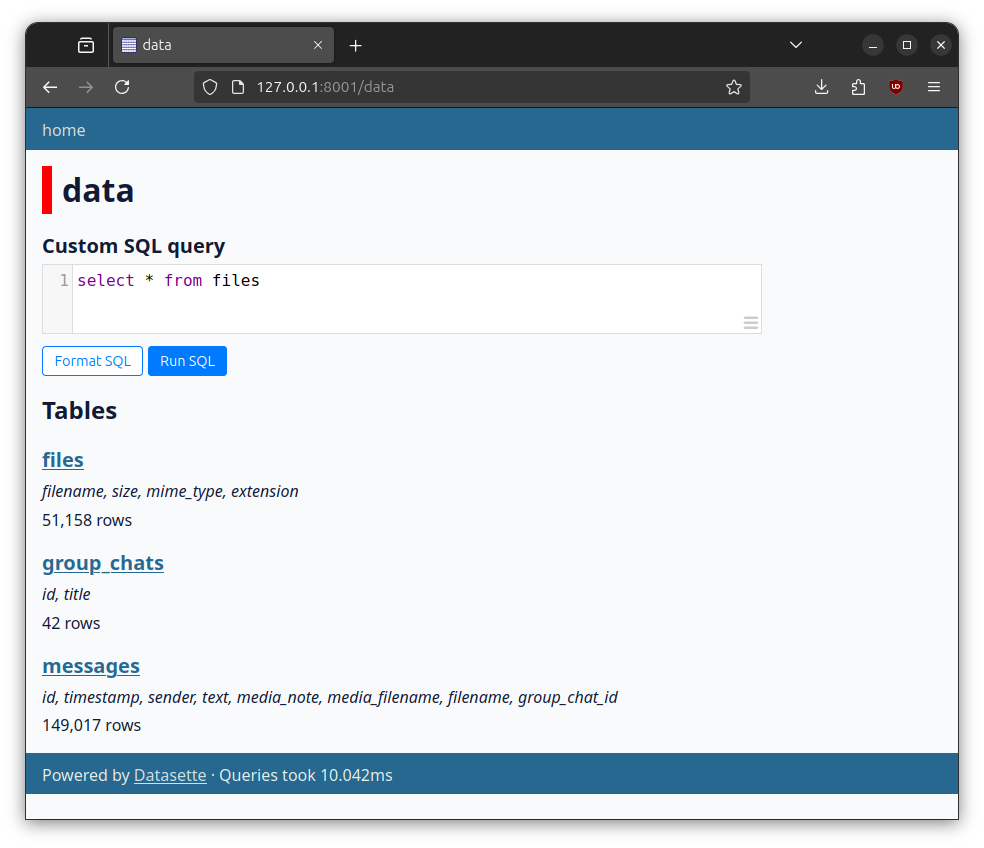
The SQL database contains these three tables:
- files includes a row for every file in the Paramilitary Leaks dataset. It includes the filename, file size, and MIME type. I haven't really used this yet, but I could see it being useful eventually.
- group_chats contains all of the Telegram group chats that were discovered in the dataset – it also tracks how the names of groups chats were updated over time.
- messages is where we'll be spending the most time. It has 149,017 individual Telegram messages that can be easily filtered and sorted using Datasette.
There are a ton of features of Datasette that I'm not familiar with – I just used it for the first time a few days ago myself – so I'm going just stick with the very basics for now. Click on messages and you'll see the messages, along with ways to start filtering them:
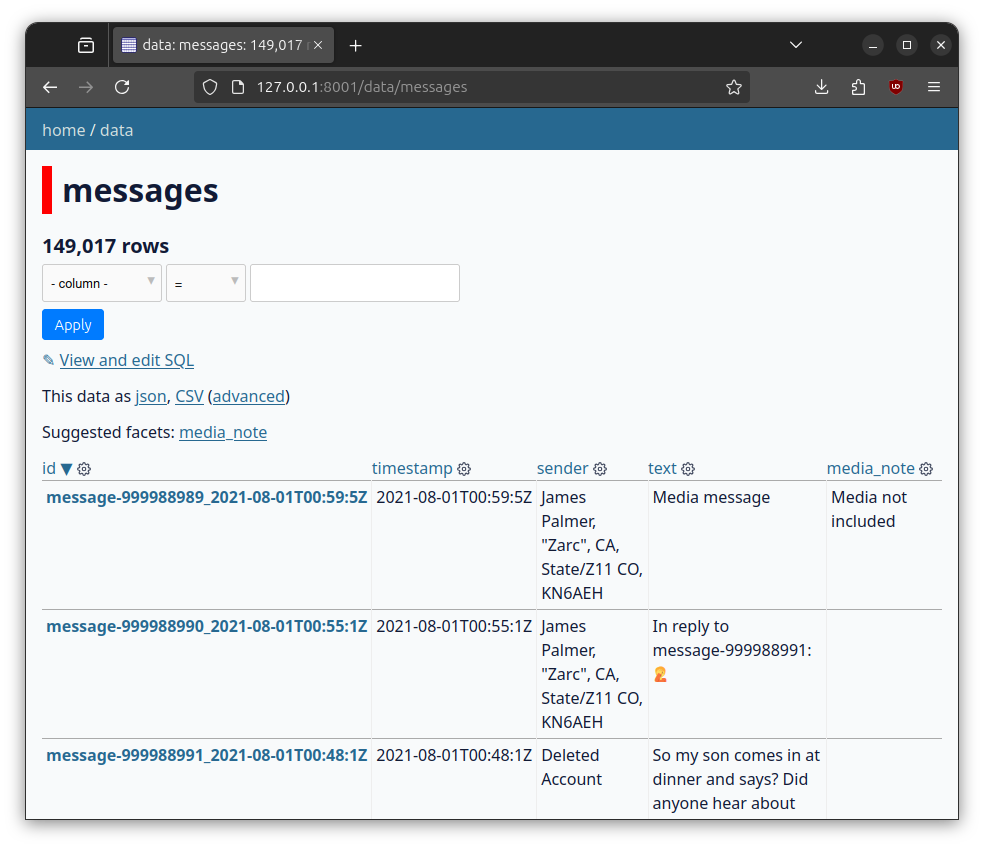
Because there are a lot of columns, there's a horizontal scrollbar, making it impossible to show all of the data in a single screenshot. Here's what a typical row might look like:
- id:
message537_2021-08-04T18:10:0Z - timestamp: 2021-08-04T18:10:0Z
- sender: WhiteShark
- text: J6 was just the beginning🇺🇸👌🏻
- filename:
AP III National/ChatExport_2023-03-12 (3)/messages2.html - group_chat_id: 10
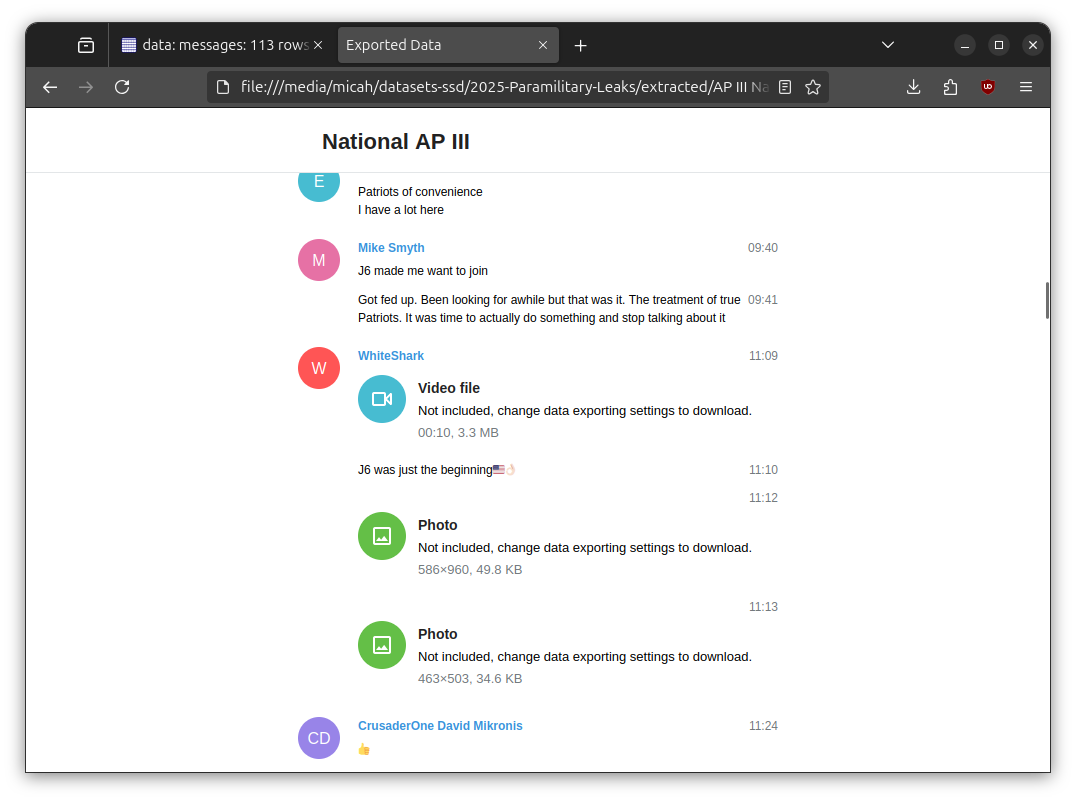
If you want to view this same message in the context of the exported Telegram chat, open filename in your browser. Here's that same message, viewed in context:
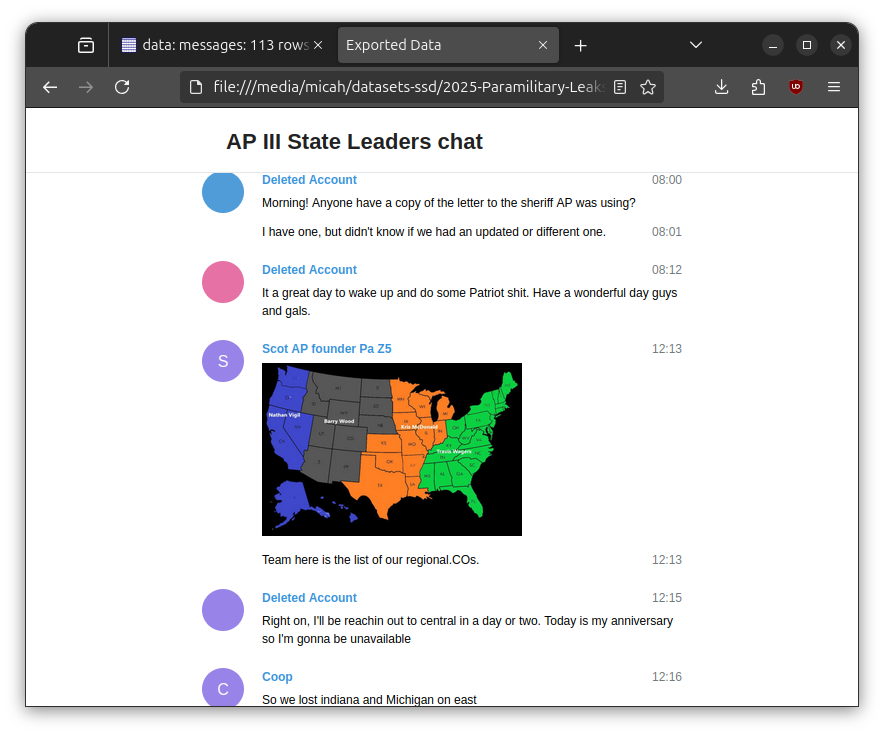
Some of the messages include media. Here's an example of a message with media:
- id:
message2199_2020-12-30T19:13:3Z - timestamp: 2020-12-30T19:13:3Z
- sender: Scot AP founder Pa Z5
- text: Media message
- media_note: image
- media_filename:
AP III State Leaders Chat/ChatExport_2023-03-20/messages3.html/photos/photo_120@30-12-2020_12-13-35.jpg - filename:
AP III State Leaders Chat/ChatExport_2023-03-20/messages3.html - group_chat_id: 11
Here's what that message looks like in context:
Back to Datasette, filtering and sorting the data is easy.
At the top there's a - column - dropdown to apply filters. Here I'm searching for messages that contain the string palestin (to encompass both "Palestine" and "Palestinian"), and I clicked timestamp to sort the messages descending (the most recent first):
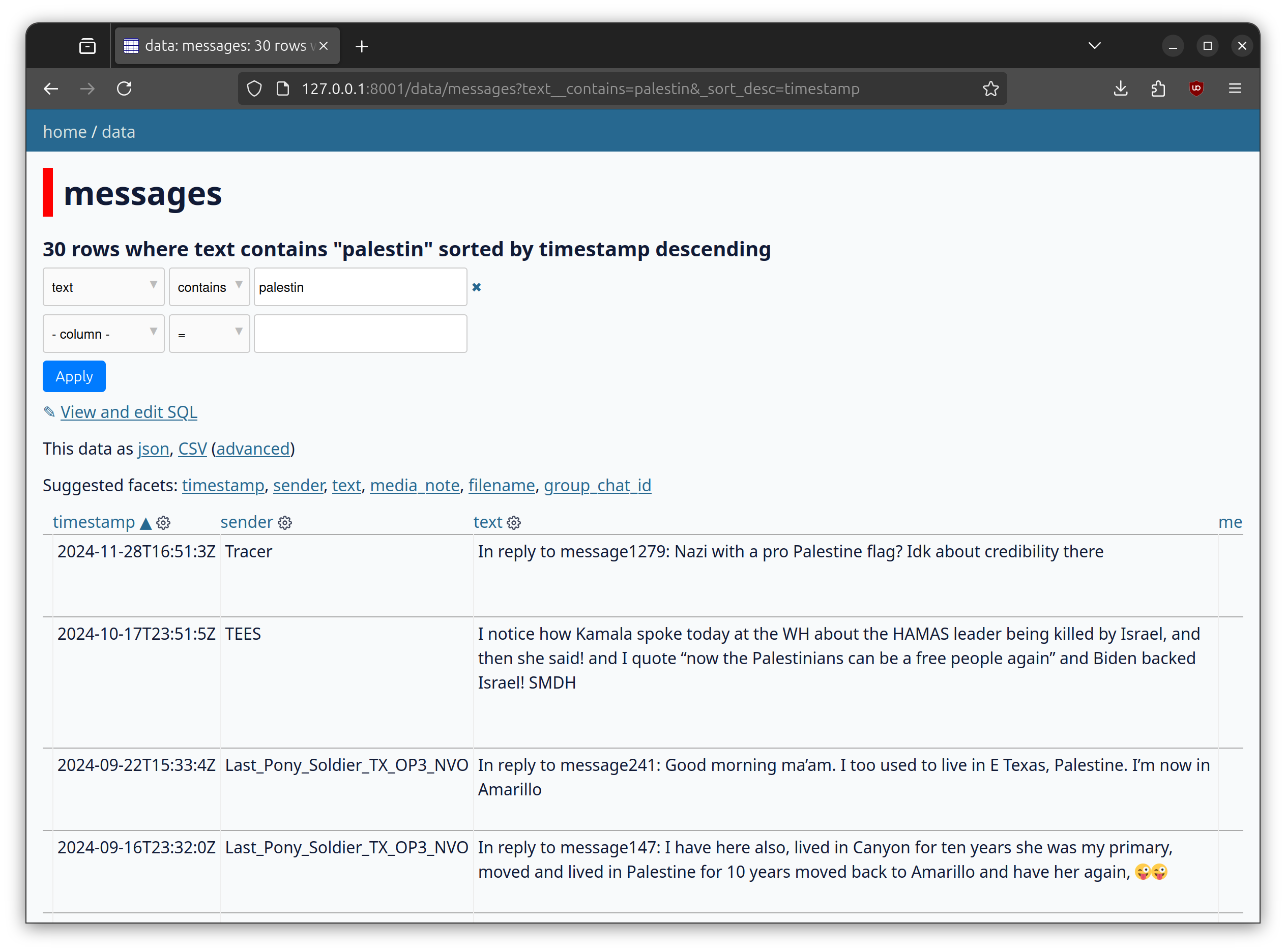
palestinThis should be more than enough to get you started researching this dataset.
Research workflow
At this point, the best way to proceed is to start digging into a specific topic. And make sure to take notes, which you can use once you're done with your research phase and ready to start writing your report (or whatever it is you plan to do with this research).
For example, maybe you live in Tennessee and are wondering how organized your local fascists are. You could start by searching the messages for Tennessee, or for the names of cities like Nashville or Memphis. You can also filter by senders who have TN in their name – AP III is obsessed with hierarchies, and unlike anti-authoritarian groups, they actually have defined chains of command – and maybe you'll discover who the local organizers there are.
Spend some time reading the chats that show up in your search queries and make sure to load the original message*.html files too, so you can understand the context and who is saying what. Whenever anything stands out, take notes.
After doing this initial research, you should have a better idea of how to proceed. Maybe there was a specific local event that militia chuds showed up at. Perhaps you can see what they were saying and doing around that event from this dataset, and then you can write it up as an article.
While I'm researching this dataset I found that it works best to have three windows open:
- A browser with Datasette loaded so I can make searches and read through the messages.
- A browser where I can load the original
message*.htmlfiles, as needed. This is especially necessary whenever you come across a media message – this way you can view the image, watch the video, or listen to the voice message. - A text editor for notes. Personally I use Visual Studio Code and write my notes in Markdown, but it really doesn't matter. You can use Microsoft Word, Notepad, or even Google Docs (though, I recommend keeping this stuff off Google if you can avoid it).
When you're ready to write up your article – or whatever you plan to do with this research – you can reference your notes, which in turn references the dataset itself.
Protecting yourself
Along the way, I'm also taking the following basic steps to protect myself:
For doing this research, I made a new Firefox browser profile that's configured to clear browser data when I close the browser. Your choice of browser isn't too important. The important thing is separating your research web browser from your normal web browser.
I use burner accounts when I need them. For example, if I find a Facebook link in the data and it requires an account to view, I'll make a new Facebook account for this purpose. (Keep track of all your burner accounts in a password manager.)
I use a VPN while doing this research. This way I can click links and do online research and not need to worry about sharing my home IP address to any of the sites I'm visiting.
Next steps
For the next installment, rather than teaching how to analyze this dataset, I'm going to do some analysis myself. Specifically, I'm going to read through all of the Telegram messages from Scot Seddon, the founder of AP III National.
Remember to subscribe to my newsletter . And if you want to support my work, sign up as a paid supporter or buy a copy of Hacks, Leaks, and Revelations: The Art of Analyzing Hacked and Leaked Data.
Please consider donating to Distributed Denial of Secrets. It's a tiny, scrappy, underfunded non-profit collective that also runs the world's largest public library of hacked and leaked datasets like this one. They could really use your support.
Also, John Williams, the person who spent years of his life infiltrating the American militia movement to make this data available, asked me to share a few links:
- You can find him on Reddit as u/shitshowshaman.
- You can support his Patreon.
- And you can donate to his "Keep John safe while he exposes America's far-right militia" crowdfunding campaign.