
Exploring the Paramilitary Leaks
In January, Distributed Denial of Secrets published over 200 gigabytes of chat logs and recordings from paramilitary groups and militias, including American Patriots Three Percent (APIIII) and the Oath Keepers. The files were obtained by John Williams, a wilderness survival trainer who spent years deep undercover infiltrating the American militia movement – if you haven't read Joshua Kaplan's reporting on this in ProPublica, I recommend it.
It's come to my attention that this dataset is rather challenging for journalists and researchers to wrap their heads around. I wrote a book, Hacks, Leaks, and Revelations, aimed at teaching journalists and researchers how to analyze datasets just like this. I'm also quite interested in what's in here myself – this is one of the only datasets I've downloaded since I left The Intercept, actually. So, I figured I'd write a series of posts publicly exploring this dataset and sharing my findings.
I'd love for this to be an interactive experience! If you're interested in this dataset, please subscribe to get these posts emailed directly to your inbox (I just converted my blog into a newsletter). If you're subscribed, you can post comments. If you have questions about the dataset or my finding or anything else, or if you have suggestions on what parts of it to dig into, post comments and I'll engage. If you want to support my work, considering becoming a paid supporter.
You're currently reading the first installment in this series.
- Part 2: Step-by-step guide to reading the leaked militia chats yourself
- Part 3: The AP III militia's fraudulent charity front group
Accessing the dataset
You can find instructions on how to access this dataset on the Paramilitary Leaks page of the DDoSecrets website. Specifically:
- If you want to use BitTorrent, you can download the torrent file or use a magnet link.
- If you want to download directly with a web browser or with
curl, the data is available at: https://data.ddosecrets.com/Paramilitary Leaks/Paramilitary Leaks/ - If you want to search the data in Aleph (an excellent tool that lets you index datasets and then search them for keywords), DDoSecrets has indexed it here in the Library of Leaks: https://search.libraryofleaks.org/datasets/59
If you want to download this locally, I recommend getting a dedicated USB hard drive for working with datasets.
Chapter 1 - Exercise 1-2: Encrypt a USB Disk
Chapter 2 - Distributed Denial of Secrets
Chapter 2 - Download Datasets with BitTorrent
Chapter 5 - Introducing Aleph
A brief tour of the data
I still haven't gone through much of this data myself so this tour is far from complete. But here's what I can tell you so far.
After downloading all of the compressed files of this dataset and extracting them with 7-zip, you'll end up with the following folders:
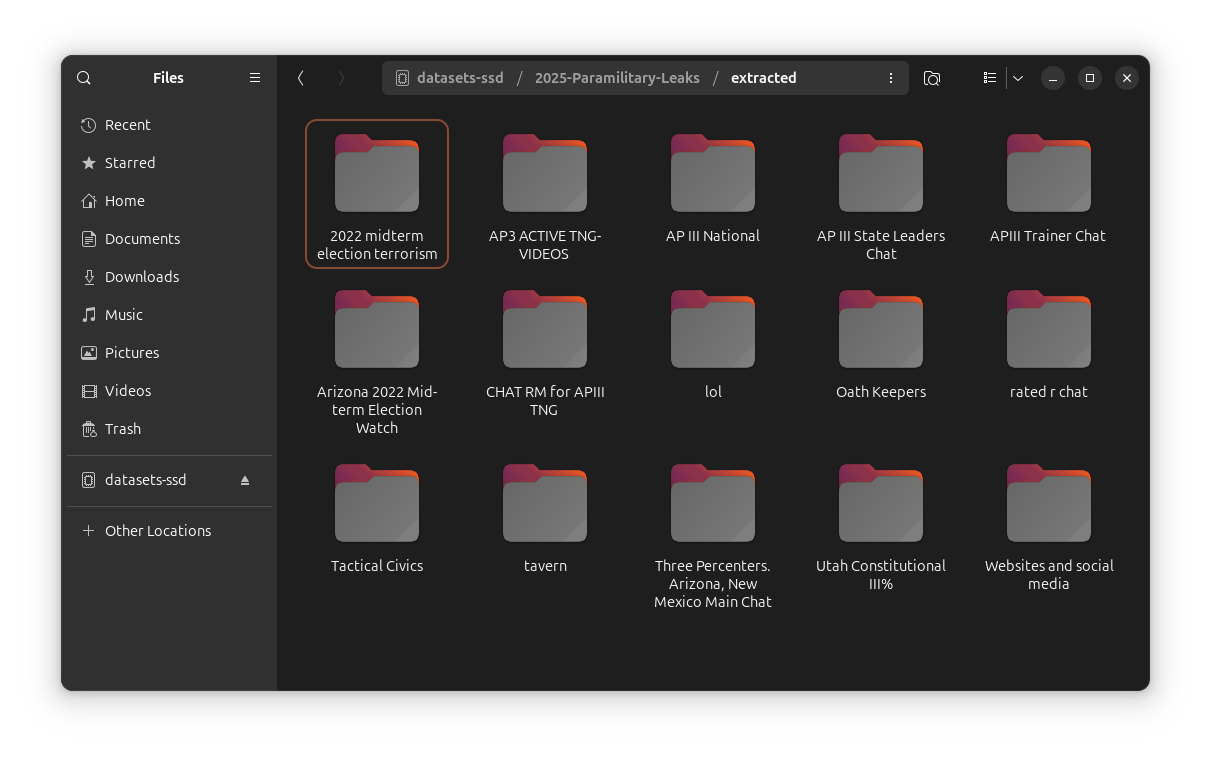
If you click around these folders you'll find several folders that start with ChatExport_ followed by a date, plus a smattering of screenshots and documents. For example, here's what's in the AP III State Leaders Chat folder:
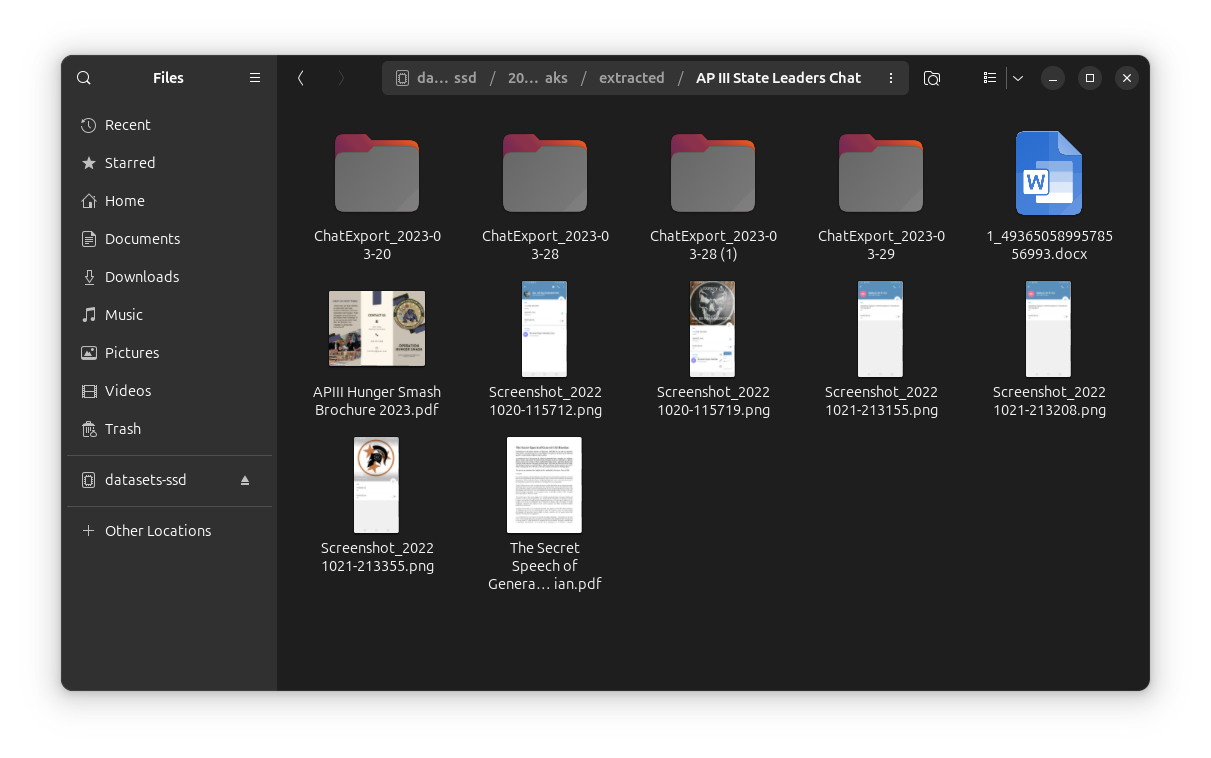
AP III State Leaders Chat folderIf you look inside the ChatExport_ folders, they have one or more messages.html files, along with several folders for files, photos, videos, voice messages, and so on. When you open a messages.html file in a browser, it becomes clear that these are exports of Telegram channels. Here's a screenshot from AP III State Leaders Chat/ChatExport_2023-03-29/messages5.html:
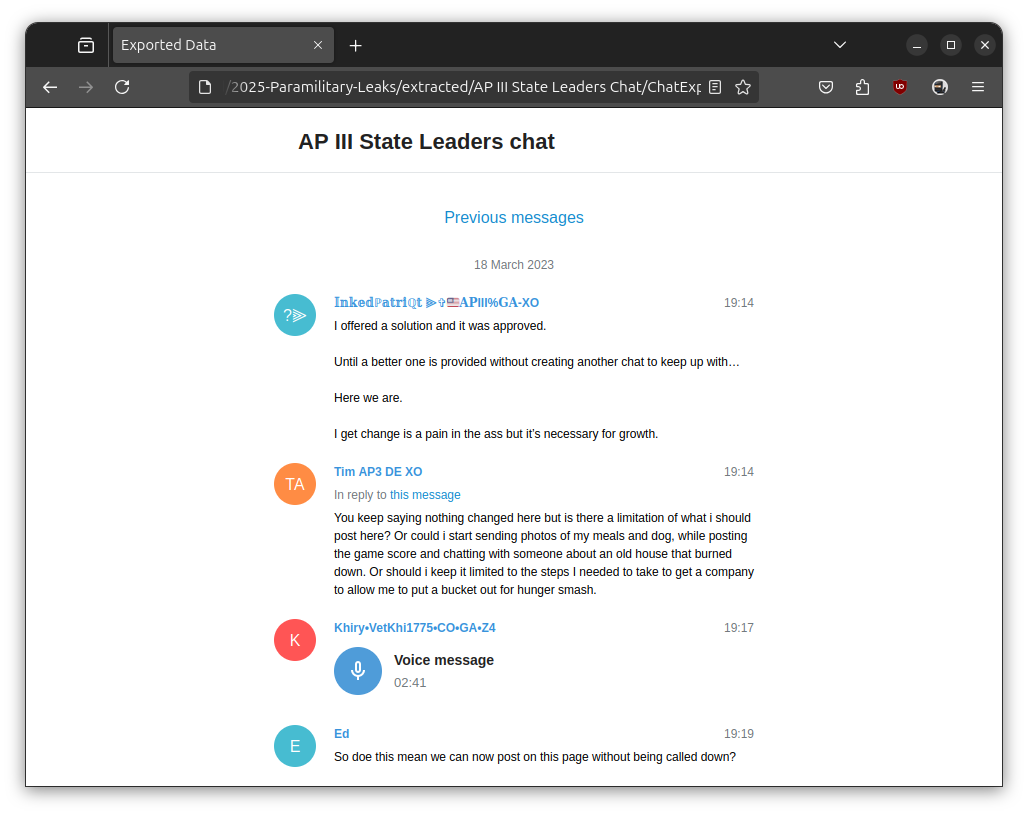
The dataset is, essentially, tons of exports of different Telegram channels from different times, complete with all of the stuff uploaded to those channels. There's a lot in there.
For example, I write a little script to find the biggest files and I discovered multiple full-length films in there: several conspiracy documentaries like Cages - Epic Human Trafficking Truth (2023).mp4, PlanD3 - Ivermectin The Truth_1080.mp4, Fake News A True History 2019.1080p.mp4, as well as The Passion of the Christ - Full Movie.mp4.
There are tons of recordings of Zoom calls. Tons of voice messages. Tons of Office documents. Random drone footage from their gun practice. And so much more that I haven't dug into yet.
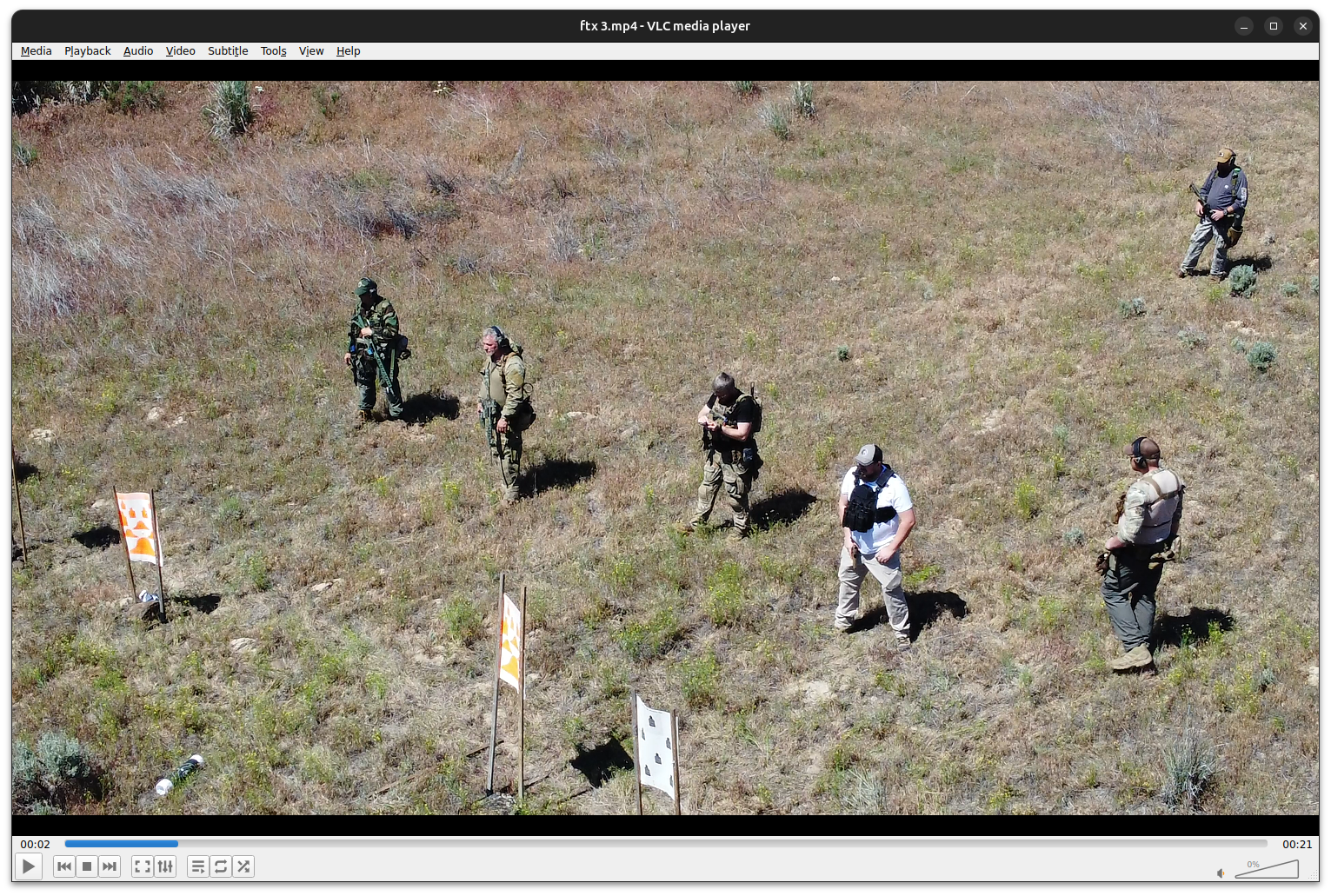
AP III State Leaders Chat/ChatExport_2023-03-28/video_files/ftx 3.mp4This is why this dataset is hard to wrap your head around: there's just sooo much here. It would take a ridiculous amount of time to try to manually read through it all. Also, at a glance at least, it appears that the bulk of it is idle chatter and conspiracy nonsense, presumably with evidence of crimes sprinkled in here or there.
Searching the data with Aleph
A good way to get started, without even having to download the dataset, is to search it using the Library of Leaks Aleph server. This obviously won't search everything – it won't include anything said in these Zoom meeting recordings or voice messages, for example. But it's a great starting place.
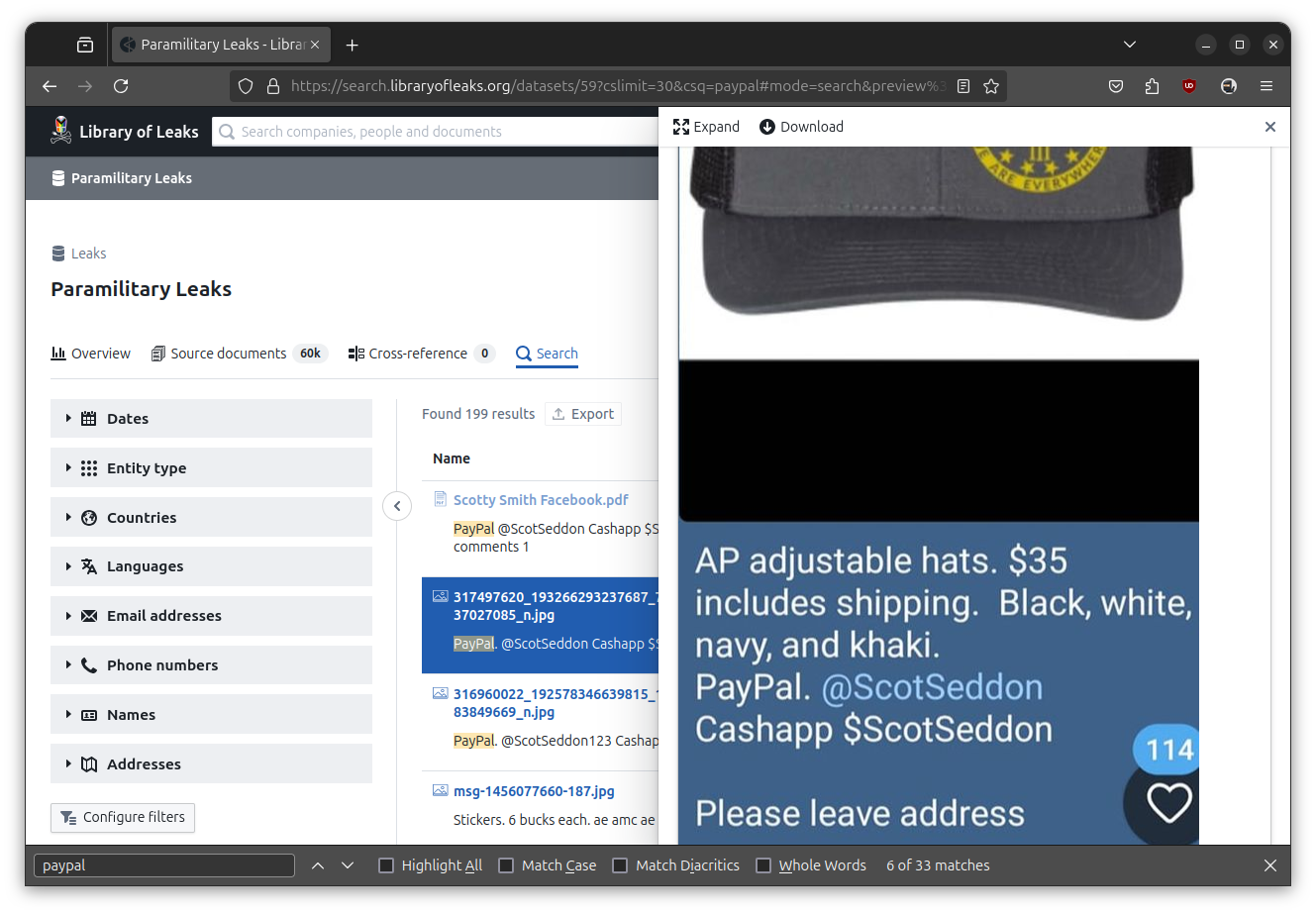
Just like other Americans, militia wingnuts use services like PayPal. When I search for "paypal" there are 199 results. Here's one of the top results, a screenshot with someone selling AP III hats, with PayPal and Cashapp usernames:
Who is Scot Seddon? I could do outside research – like searching DuckDuckGo and Google for "Scot Seddon" and the username scotseddon – but first, I'm going to search the dataset itself. When I search Aleph for his name, the first result is the file AP III State Leaders Chat/ChatExport_2023-03-20/files/1_4902439503181906326.pdf:
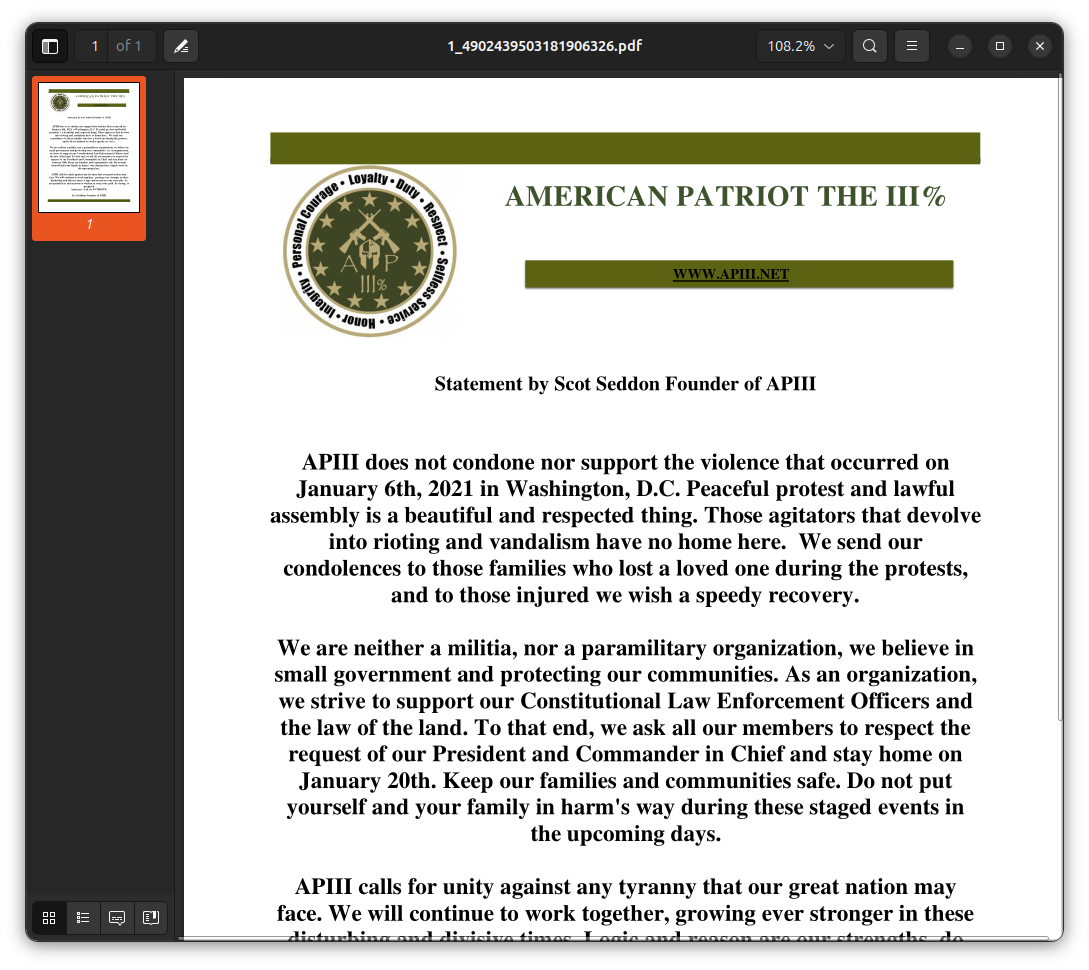
Ahh, so he's the founder of American Patriot Three Percent, and here's his statement disavowing the violence from January 6, 2021. Looking at the metadata of this PDF, it was created on January 16, 2021. I wonder what Scot thinks about January 6 these days, after Trump was re-elected in 2024.
In all likelihood, I can find out exactly what he thinks, because he probably posted about it to his militia buddies in Telegram, and it's probably in this dataset. The problem is, there's no easy way to quickly filter out messages from him, or even to tell which of these exported Telegram channels he was part of. I think that will be the first problem I solve.
For example, here's one of the Aleph search results for "Scot Seddon":
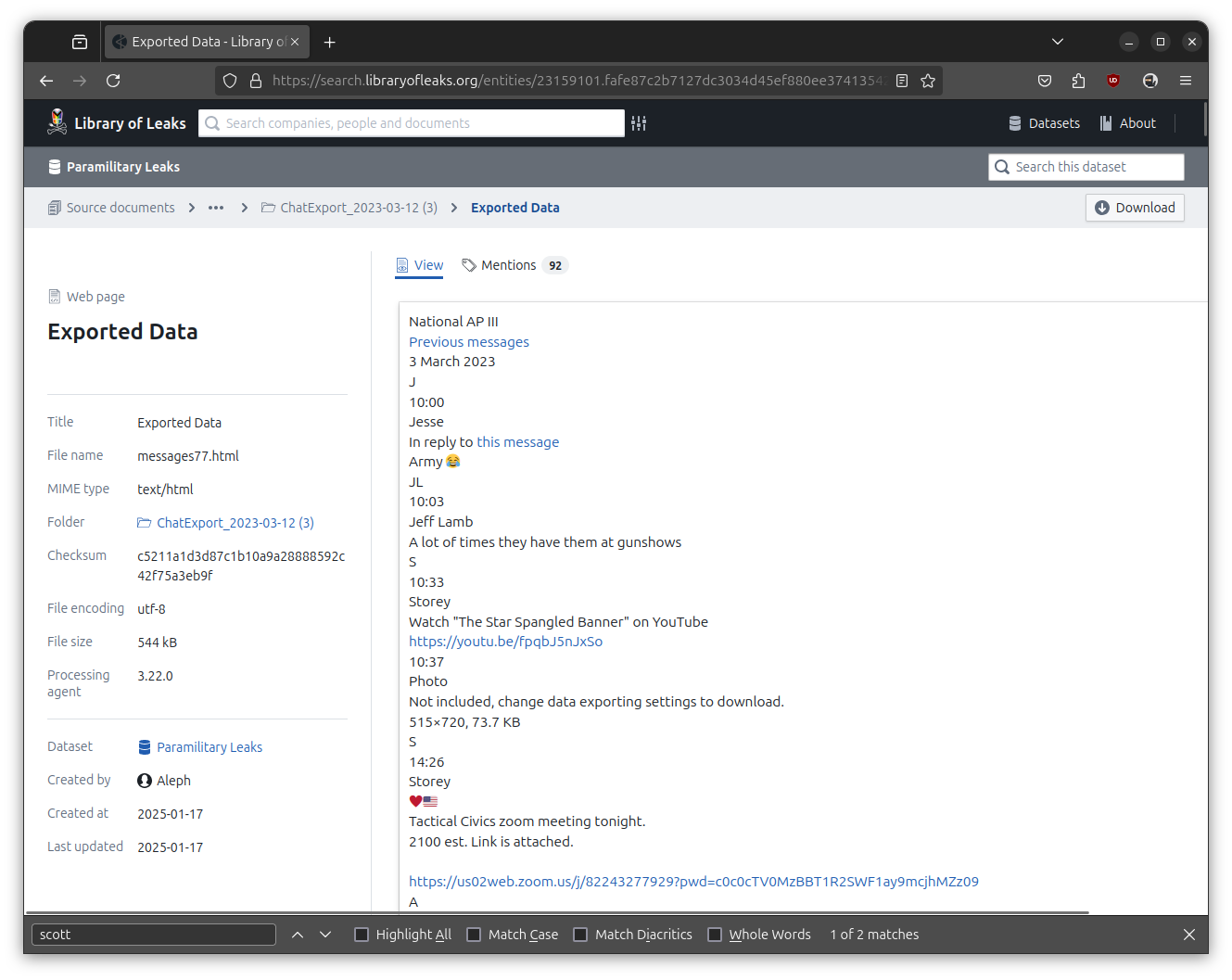
This is impossible to read from within Aleph. So, I'll proceed by opening AP III National/ChatExport_2023-03-12 (3)/messages77.html from my downloaded version of the data. (And yes, this is page 77 of messages in this exported Telegram channel.)
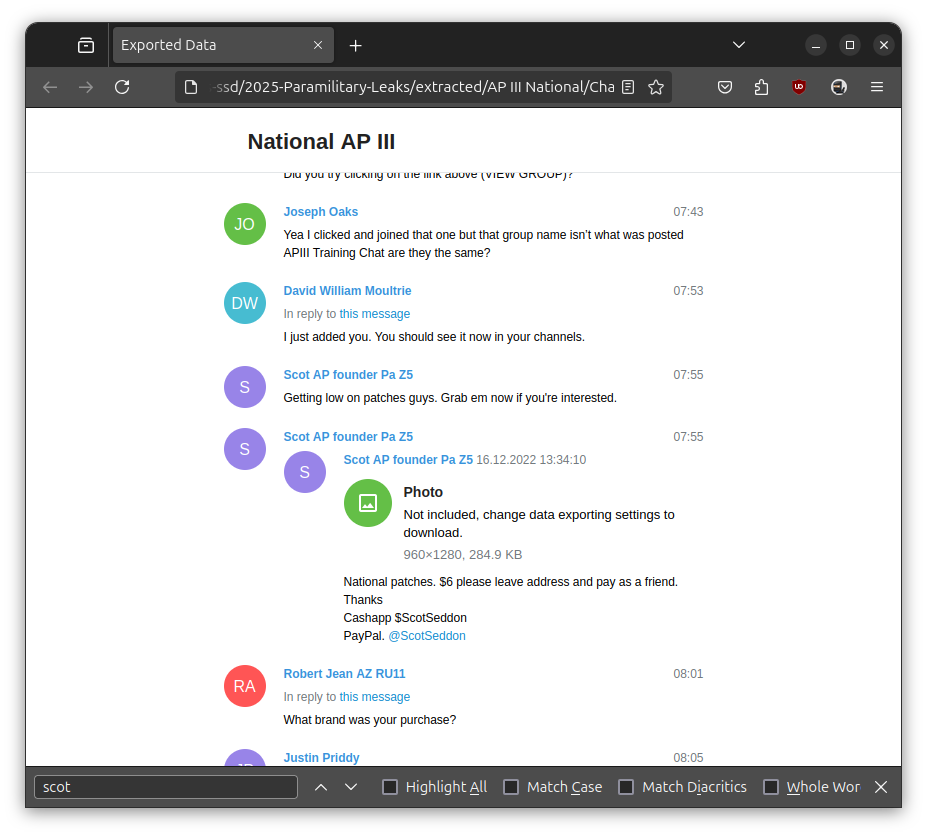
This is much more readable – but still, I don't think I can bring myself to sit down and read 77 pages of these messages right now. And that's just this one export of this one Telegram channel.
Next steps
This dataset has lots of exported Telegram channels in HTML format. And while it's missing a lot of useful data (like, Telegram usernames or IDs), the HTML actually does include quite a bit:
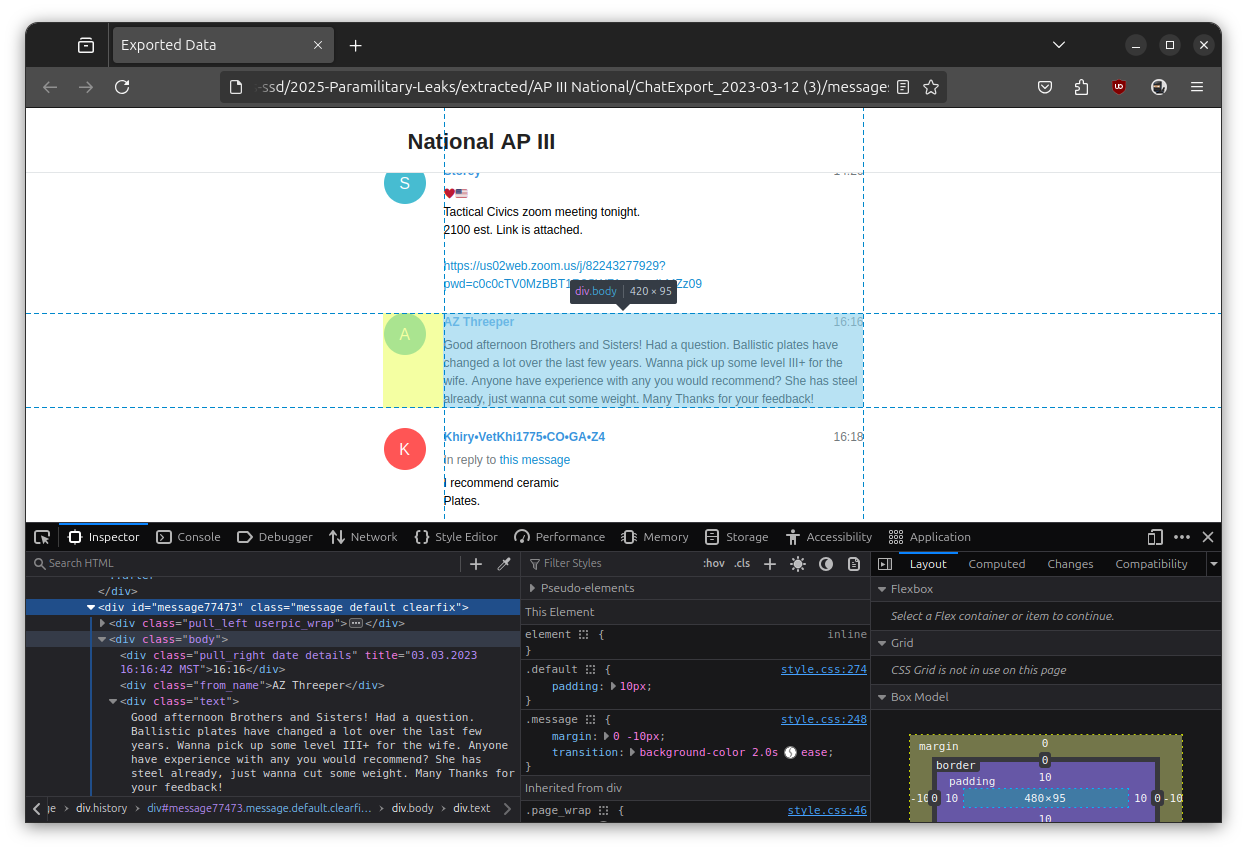
As you can see in this screenshot, the div that contains this message includes the timestamp of the post, the user's display name, and the text of the post. The dataset also includes images, audio files, and other types of attachments too associated with each message.
So given that, here's the challenge: write a script that will browse through the dataset, loading every HTML file in every exported Telegram chat, extract all of the messages, and save them to a single SQL database.
Chapter 7: An Introduction to Python
Chapter 8: Working with Data in Python
Chapter 11: Parler, the January 6 Insurrection, and the JSON File Format
Chapter 12: Epik Fail, Extremism Research, and SQL Databases
Here's probably how I'll do it:
- Create a SQLite schema, probably using SQLAlchemy, for storing Telegram messages. Each message should include things like the timestamp, display name, text, and the filename of the file it was found in.
- Recursively loop through all folders in the dataset finding all folders that start with
ChatExport_– these are the chat exports. - In each of those, loop through all the files looking for
message*.html– these are where the messages are. - For each of those, load the HTML file and parse it using a library like Beautiful Soup. Loop through the messages, extract each piece of information, and then insert the message into the SQLite database.
At the end, I'll have a single database of Telegram messages from the whole dataset. I'll be able to query it to, for example, show me all messages from Scot Seddon sorted chronologically. This will make it simple to see what he was saying in the lead-up to January 6, immediately after January 6, and then what he's saying about Trump these days, after he was re-elected.
Okay, that's it for this installment! For next time, I'll try to have this script written. My plan is to publish it on GitHub so you can use it to generate your own SQL database based on HTML Telegram exports like this.
If you're a programmer and you have some time to give it a shot yourself, by all means do it and let me know!
Remember to subscribe to my newsletter. And if you want to support my work, sign up as a paid supporter or buy a copy of Hacks, Leaks, and Revelations: The Art of Analyzing Hacked and Leaked Data.
And please consider donating to Distributed Denial of Secrets. It's a tiny, scrappy, underfunded non-profit collective that also runs the world's largest public library of hacked and leaked datasets like this one. They could really use your support.